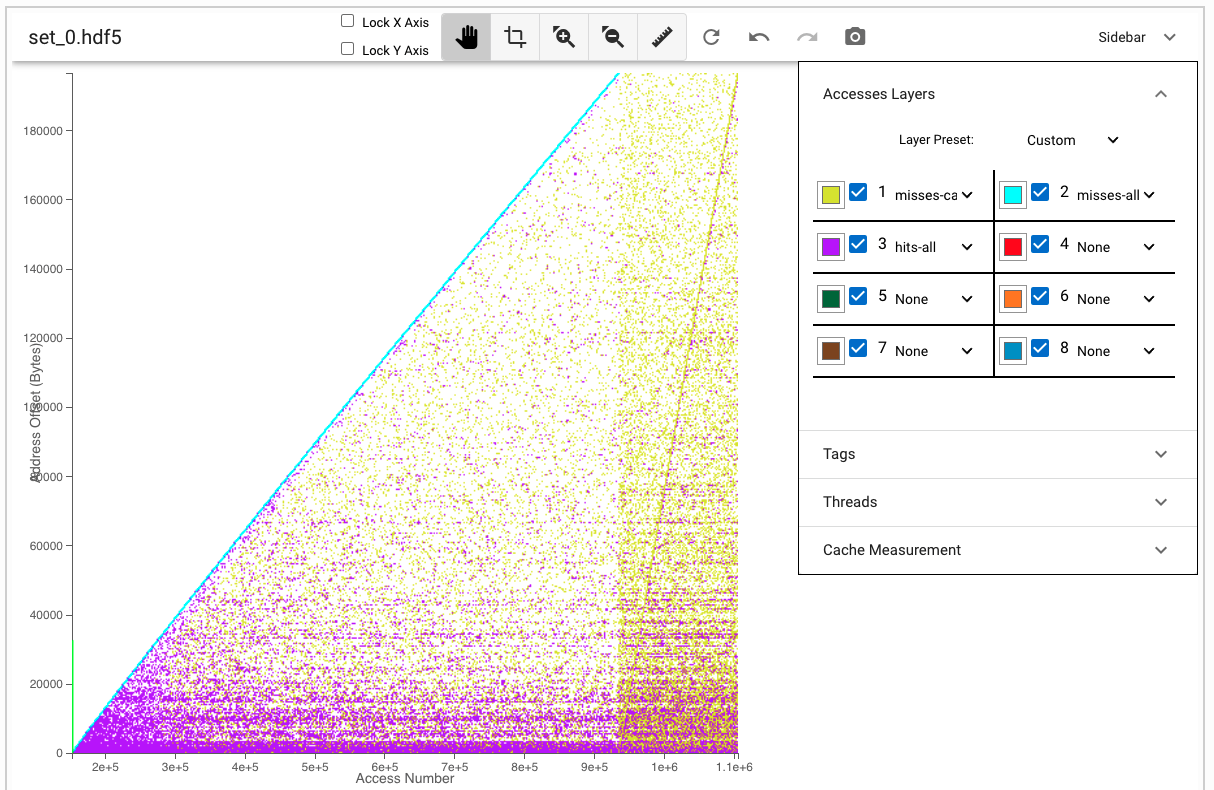
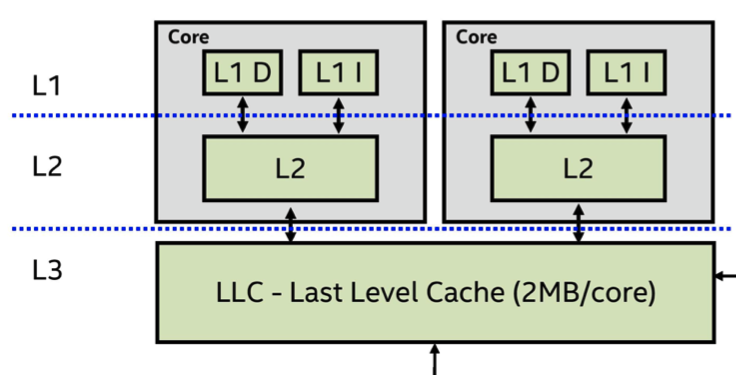
#include <stdlib.h>
#include<iostream>
#include"cfiddle.hpp"
#include<map>
#include<vector>
#include<algorithm>
#include"ReferenceAllocator.hpp"
#if USE_INSTRUCTOR_SOLUTION == 1
# include"admin/FastAllocator.hpp"
#else
# if USE_INSTRUCTOR_SOLUTION == 2
# define ReferenceAllocator AlignedAllocator // This is terrible. I'm sorry.
# include"ReferenceAllocator.hpp"
# undef ReferenceAllocator
# else
# include"AlignedAllocator.hpp"
# endif
#endif
template<class Allocator>
void exercise(Allocator * allocator, size_t count, int iterations, uint64_t seed, bool cleanup = false) {
// Interesting allocator behaviors an bugs emerge when the allocator
// has to allocate and free objects in complex patterns.
//
// To simulate that, we allocate count items and then, on each
// iteration, free about 1/4 of them and replace them with new items.
std::vector<typename Allocator::ItemType *> items(count);
for(unsigned int i = 0; i < count; i++)
items[i] = NULL;
for(int i = 0; i < iterations; i++) {
for(unsigned int j = 0; j < count; j++) {
if (items[j] == NULL) {
items[j] = allocator->alloc();
}
}
for(unsigned int j = 0; j < count; j++) {
fast_rand(&seed);
if (seed & 0x3) {
allocator->free(items[j]);
items[j] = NULL;
}
}
}
if (cleanup) {
for(unsigned int j = 0; j < count; j++) {
if (items[j]) {
allocator->free(items[j]);
items[j] = NULL;
}
}
}
}
template<class Allocator>
void bench(uint64_t count, uint64_t seed, bool do_exercise, const char * tag) {
auto alloc = new Allocator;
if (do_exercise){ // warm it up.
exercise<Allocator>(alloc, 4000, 20, seed);
}
start_measurement(tag);
exercise<Allocator>(alloc, count/16, 16, seed);
end_measurement();
delete alloc;
}
template<class Allocator>
void microbench(uint64_t count, uint64_t seed, bool do_exercise, const char * alloc_tag, const char * free_tag) {
auto alloc = new Allocator;
if (do_exercise) { // get the allocator warmed up.
exercise<Allocator>(alloc, 4000, 20, seed);
}
std::vector<typename Allocator::ItemType*> items(count);
start_measurement(alloc_tag);
for(uint64_t i = 0; i < count; i++) {
items[i] = alloc->alloc();
}
end_measurement();
if (do_exercise) {
exercise<Allocator>(alloc, 4000, 20, seed);
}
start_measurement(free_tag);
for(uint64_t i = 0; i < count; i++) {
alloc->free(items[i]);
}
end_measurement();
delete alloc;
}
//BEGIN
struct MissingLink {
struct MissingLink * next;
};
extern "C"
struct MissingLink* __attribute__((noinline)) do_misses(struct MissingLink * l, uint64_t access_count) {
for(uint i = 0; i < access_count; i++) {
l = l->next;
}
return l;
}
template<class Allocator>
void miss_machine(uint64_t link_count, uint64_t access_count, uint64_t seed, const char * tag) {
auto alloc = new Allocator; // create the allocator.
exercise<Allocator>(alloc, 10000, 20, seed); // warm it up.
std::vector<struct MissingLink *> links(link_count); // Storage for the links
for(auto &i : links) { // allocate them.
i = alloc->alloc();
i->next = NULL;
}
std::shuffle(links.begin(), links.end(), fast_URBG(seed)); // randomize the order of the links
for(uint i = 0; i < links.size() -1; i++) {
links[i]->next = links[i+1]; // Make the next pointers reflect the ordering.
}
links.back()->next = links.front(); // complete the circle
struct MissingLink * l = links[0];
start_measurement(tag);
l = do_misses(l, access_count); // Do the misses.
end_measurement();
delete alloc;
}
//END
// Call the starter code
extern "C"
void allocator_bench_starter(uint64_t count, uint64_t seed) {
bench<ReferenceAllocator<uint8_t[3], 16>>(count, seed, true, "bench-3-bytes" );
bench<ReferenceAllocator<uint8_t[125], 32>>(count, seed, true, "bench-125-bytes" );
bench<ReferenceAllocator<uint8_t[4096], 4096>>(count, seed, true, "bench-4096-bytes");
}
extern "C"
void allocator_microbench_starter(uint64_t count, uint64_t seed) {
microbench<ReferenceAllocator<uint[4], 8>>(count, seed, true, "alloc-4-bytes", "free-4-bytes");
microbench<ReferenceAllocator<uint[1024], 4096>>(count, seed, true, "alloc-1024-bytes", "free-1024-bytes");
}
extern "C"
void miss_machine_starter(uint64_t link_count, uint64_t access_count, uint64_t seed) {
miss_machine<ReferenceAllocator<struct MissingLink, sizeof(struct MissingLink)> >(link_count, access_count, seed, "miss-machine");
}
// Call your code
extern "C"
void allocator_bench_solution(uint64_t count, uint64_t seed) {
bench<AlignedAllocator<uint8_t[3], 16>>(count, seed, true, "bench-3-bytes" );
bench<AlignedAllocator<uint8_t[125], 32>>(count, seed, true, "bench-125-bytes" );
bench<AlignedAllocator<uint8_t[4096], 4096>>(count, seed, true, "bench-4096-bytes");
}
extern "C"
void allocator_microbench_solution(uint64_t count, uint64_t seed) {
microbench<AlignedAllocator<uint[4], 8>>(count, seed, true, "alloc-32-bytes", "free-32-bytes");
microbench<AlignedAllocator<uint[256], 4096>>(count, seed, true, "alloc-1024-bytes", "free-1024-bytes");
}
extern "C"
void miss_machine_solution(uint64_t link_count, uint64_t access_count, uint64_t seed) {
miss_machine<AlignedAllocator<struct MissingLink, sizeof(struct MissingLink)> >(link_count, access_count, seed, "miss-machine");
}